FUn: A Framework for Interactive Visualizations of Large, High Dimensional Datasets on the Web
- Introduction / Architecture
- Examples
- Existing Frameworks / Components and Benchmarks
- Setting-Up the Framework using Docker
- User Tutorial
- Documentation
- Links (repositories, docker images, npm and bower packages)
Introduction / Architecture
From architectural point of view, the framework consists of three parts:
- The data pre-processing, which is done by the user using an arbitrary data source as input. A set of bash and Python scripts is provided to facilitate easy conversion to a format readable by the web services.
- Two to three applications are hosted on one or more servers accessible by the user through HTTP and WebSocket.
- Underdark Go is the data service, distributing the pre-processed data stored on the server to the users accessing them through web browsers. The application is written in Go to enable fast and memory-efficient access to the data.
- Faerun is a simple web application connecting to Underdark Go over HTTP and transffering data through a WebSocket channel.
- Optional: Planes is a web service which can be deployed to enable the user to project custom data on the data sets loaded from Underdark Go. The PCA model generated during the data pre-processing step are used to enable this operation.
-
Three JavaScript modules distributed by Faerun run in the users browser.
- The Faerun network communication script(s) which enable communication with Underdark Go through WebSocket and Planes (the PCA service) by AJAX.
- Lore.js is a visualization library which was developed in-house.
- SmilesDrawer is a SMILES drawing library (also developed in-house), enabling fast server-less drawing of molecular structures.
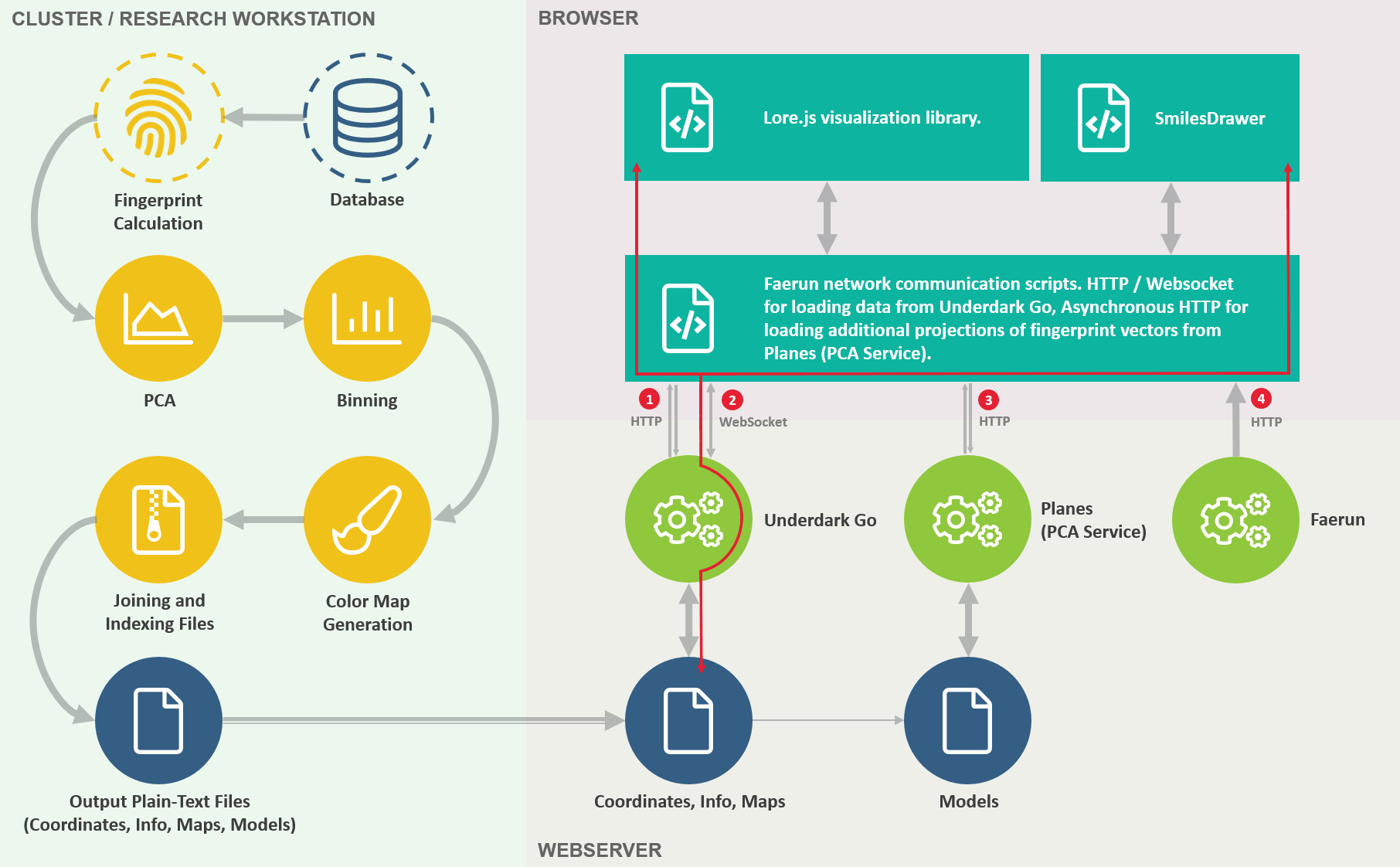
Details on the connections between the client (Faerun) and the server (Underdark):
- Upon initially loading the website, a persistent WebSocket connection is opened (Handshake / HTTP upgrade) over HTTP.
- All further communication between the client (Faerun) and the server (Underdark) takes place over WebSocket and thus bidirectionally (over a single, full-duplex, open TCP connection), removing the overhead of HTTPs request / response scheme.*
- User supplied data (SMILES strings of molecules in the reference implementation) is posted (POST request) to the PCA service using asynchronous HTTP (AJAX). The server then responds with JSON data. This data contains the coordinates of the user supplied data as projected onto the currently visualized space.
- The server part of Fearun does not send or recieve any data from the client part. It is just an nginx instance hosting (and thus unidirectionally delivering) static HTML, JavaScript and CSS files. *Exchanging messages, such as sending additional information to the user upon interaction with a data point, is of great importance for providing a responsive experience. WebSocket, compared to AJAX, enables such a communication between client and server, as benchmarks have shown.
- A full stack implementation is the SureChEMBL Viewer.
- Examples on how to load and visualize local files (useful for creating native JavaScript applications) can be found in the Lore.js git repository. The examples, as well as the example data (in .csv and .pce format) can be found in the examples directory.
- THREE.js is currently the most versatile but also the most complex WebGL library available. We found that this complexity had caveats if we wished to add future functionality not provided by THREE.js since we would have to frequently adapt our code. We also wished to make changes to core functionalities such as using interleaved buffer attributes (which have become available in THREE.js since) and store vector and matrix components / elements in typed arrays rather than JavaScript object to save memory.
- We saw the need for an API geared towards data visualization rather than a general-use engine.
- THREE.js was not able to render millions of vertices while providing pixel-accurate vertex picking. (See WebDrugCS and WebMolCS).
- Underdark. The Backend Implemented Using Go
- Faerun. The Frontend Implemented in JavaScript / CSS / HTML
- Lore.js. The 3D Data Visualization Engine Written in JavaScript
- The data preprocessing toolchain. Includes the web service enabling the projection of additional user-supplied data onto the visualized data through models trained on the database.
Communication pathways shown in red are running over the WebSocket protocol.
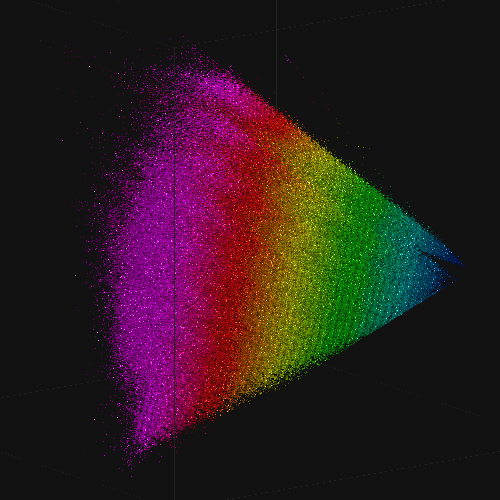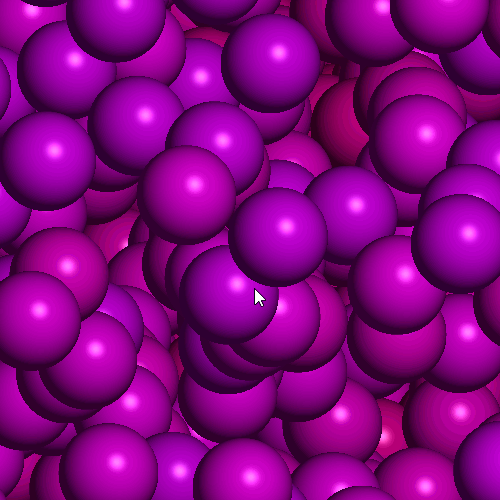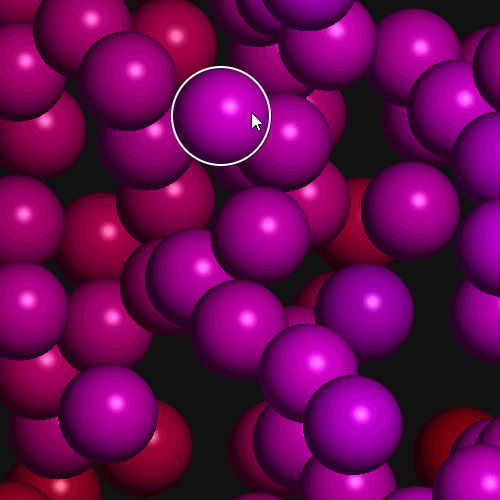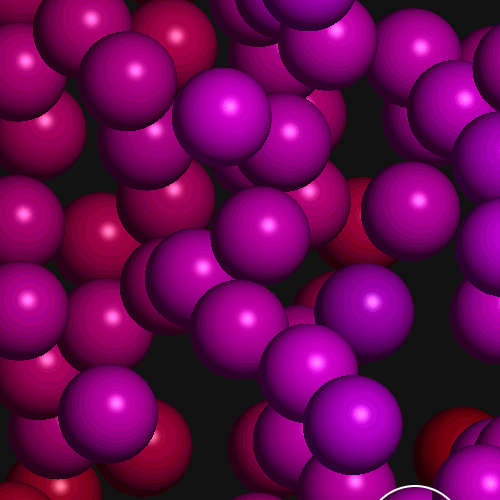
Examples
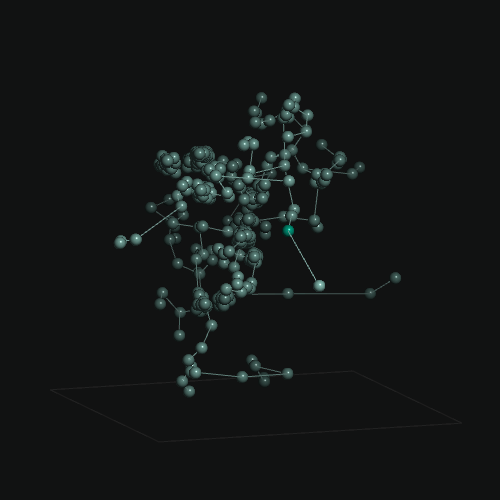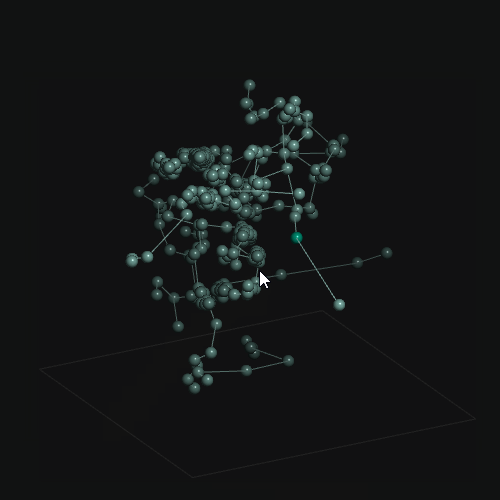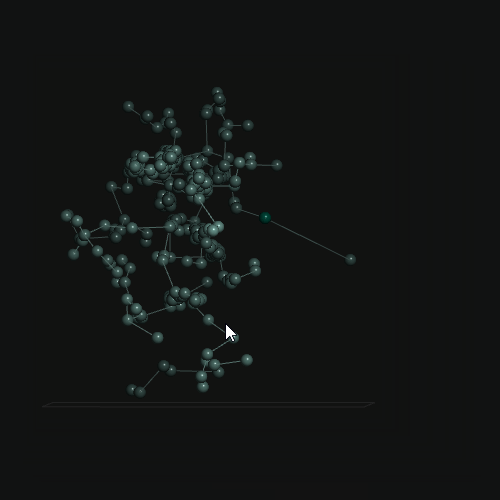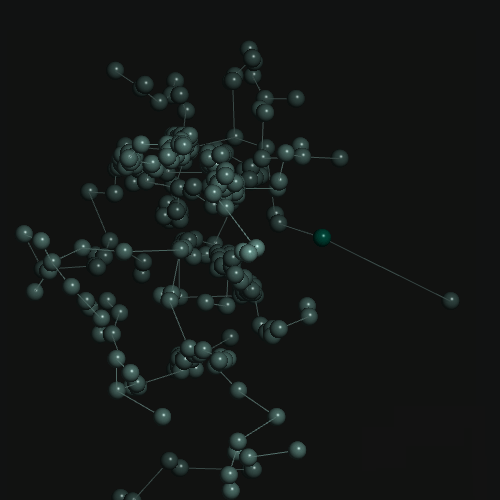
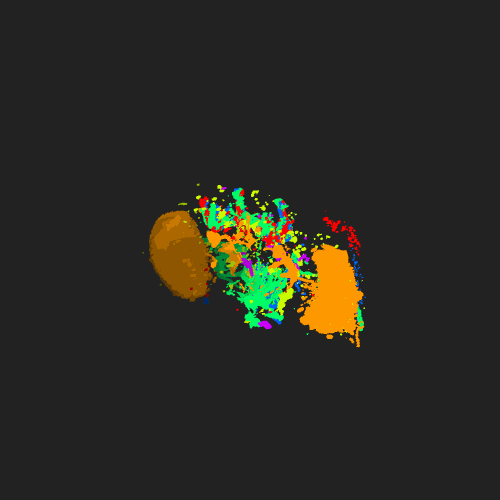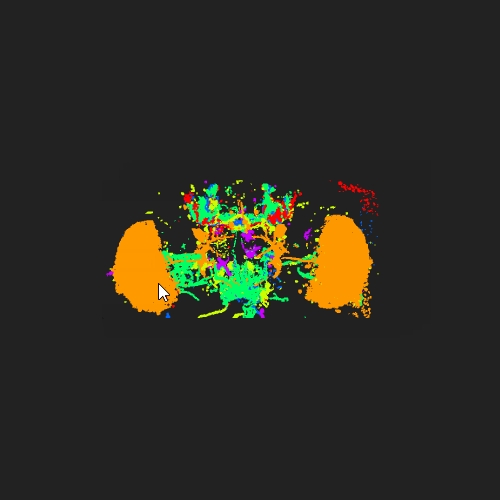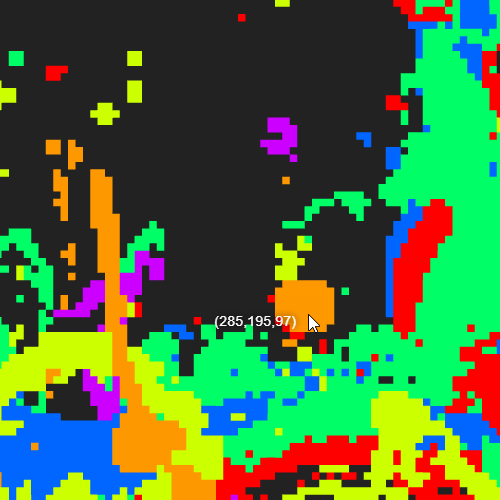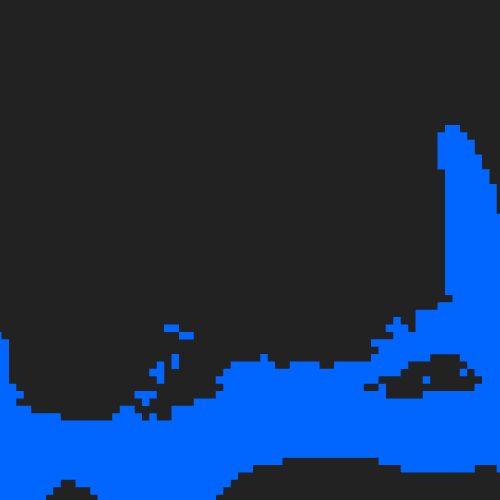
Existing Frameworks / Components and Benchmarks
We evaluated several existing components for visualizing large data sets on the web, however non of them matched our requirements. Following is a table listing the considered components:
| Component | Type | Remarks |
|---|---|---|
| THREE.js | Visualization |
THREE.js is currently the most versatile but also the most complex WebGL library available. We found that this complexity
had caveats if we wished to add future functionality not provided by THREE.js since we would have to frequently
adapt our code. We also wished to make changes to core functionalities such as using interleaved buffer attributes
(which have become available in THREE.js since) and store vector and matrix components / elements in typed
arrays rather than JavaScript object to save memory. We saw the need for an API geared towards data visualization rather than a general-use engine. THREE.js was not able to render millions of vertices while providing pixel-accurate vertex picking. (See WebDrugCS and WebMolCS). |
| d3.js | Visualization | D3.js by Bostock et al is certainly one of the, if not the, most prolific data visualization library on the web. However, even though, to the best of our knowledge, recent versions of d3 introduced canvas rendering in addition to SVG support, d3 still lacks support for performant 3D visualizations, meaning we would still have had to implement our own 3D visualization engine, but with a memory and processing overhead due to piping the data through d3. Since we do all our data manipulation server-side through pre-processing steps, or via a web-service allowing the projection of additional data into the (PC1, PC2, PC3) space, there was no need to apply d3s data processing algorithms. |
| sigma.js | Visualization | Sigma.js is a library dedicated to graph drawing and only supports the embedding of graphs in 2-dimensional spaces. However, we have shown the utility of visualizing dimensionality-reduced data in three dimensions in our previous work (WebDrugCs and WebMolCs). |
| Potree (THREE.js based) | Visualization | In addition to the remarks already made on THREE.js, Potree was not able to perform well on data which does not represent surfaces. In addition, the API is built for rendering 3D scans rather than volumetric data. |
| gnuplot | Visualization | Creates static, non-interactive (outside of the console) data visualizations. |
| Shiny (R) | Entire Framework | The performance of Shiny is not suited to visualize data on a large scale scale. |
| Flask (Python) | Backend | Go (golang) has proven to be far superior to flask in IO as well as network performance. Comparison benchmarks can be found here and here |
| ws (node.js) | Backend | Go (golang) has proven to be superior to node as well in IO as well as network performance. Comparison benchmarks can be found here. Additionally, Go has an exceptionally small memory footprint and is extremely scalable (see notes on Go in production here. |
| Redis, MongoDB, PostgreSQL | Backend | We evaluated the need for a database system for data storage and came to the conclusion that we would use plain text files as a data source as we did with previous software. It will be a simple task to add support for additional data sources through middleware for Go in the future. |
Assessing application-level performance rather than a single algorithm is rather tauning and usually carried out during beta tests. We benchmarked our framework across a range of hardware and browsers* in a group internal beta test, grouping them into four categories. The beta test was conducted using our reference implementation. The number of data points rendered has shown to be the bottleneck for the application. Benchmarks linked to in the table below also ran well on the associated device category during our tests.
| Device Category | Number of Data Points | Benchmark Link |
|---|---|---|
| Smartphones (mid-range) | 2,500,000 | benchmark |
| Smartphones (high-range) Notebooks (mid-range) |
5,000,000 | benchmark |
| Notebooks (high-range) Workstations (low-range dedicated GPU) |
10,000,000 | benchmark |
| Notebooks (high-range with dedicated GPU) Workstations (mid-range dedicated GPU) |
20,000,000 | benchmark |
*Chrome has shown the best overall performance on both desktops and mobile browsers and was chosen to be the browser used for categorization. On iOS, where only Safari is available, the performance was generally worse than on comparable Android phones.
We compared this performance to the (2D) performance of d3.js (v4), the perhaps most profilic visualization framework for the web. Even on mid-range workstations, it struggled to display a comparable number of data points using both svg (1,000,000 data points) and canvas (1,000,000 data points) drawing.
During development, we were first working with THREE.js (as we did with WebDrugCs and WebMolCs). However, several aspects of it caused us to implement our own framework.
Setting-Up the Framework using Docker
Make sure you have installed the most recent version of docker community edition.
First, a folder has to be prepared containing the data you wish to expose. Read more on how to do this in the README.md of Underdark. The Underdark container will only start if it finds a valid configuration file and the specified files and directories referenced in the config. Additionaly, a small example data set is hosted on github, it is suggested to clone the example and use it as the data folder.
git clone https://github.com/reymond-group/underdark-example-data.gitInstructions on how to provide your own data easily can be found in the README.md of the data preprocessing toolchain
Next, we run the container for Underdark. As a default, the container exposes port 8081, this can be mapped to any other port. In the following example it is mapped to port 88, since we will run the Faerun container on the same system in the next step. Additionally, the internal data folder is mapped to a folder on the host, in this case it is mapped to the repository that has been cloned in the previous step (please change the path to reflect your system).
docker run -d -p 88:8081 -v /path/to/underdark-example-data:/underdarkgo/data --name underdark daenuprobst/underdark-goFinally, we run the Faerun container. It accepts an environment variable SERVER which specifies the url of the Underdark service. In our example it runs on localhost, port 88. If no environment variable with a server address is supplied, Faerun will connect to the Underdark instance running on underdark.gdb.tools.
docker run -d -p 80:80 -e SERVER=ws://localhost:88/underdark --name faerun daenuprobst/faerunFaerun is now running on port 80 and can be accessed on http://localhost.
More detailed instructions can be found in the README.md files on the git repositories referenced under Links.
User Tutorial
The user tutorial is included in Faerun, it is shown when the page is first loaded and can be reached through the "HELP" link in the hamburger menu. The user tutorial of the reference implementation can be accessed direcly here.
Documentation
An extensive documentation on Lore.js is available here.